autoPET-II
The generalization frontier
Introduction
Positron Emission Tomography / Computed Tomography (PET/CT) is an integral part of the diagnostic workup for various malignant solid tumor entities. Due to its wide applicability, Fluorodeoxyglucose (FDG) is the most widely used PET tracer in an oncological setting reflecting glucose consumption of tissues, e.g. typically increased glucose consumption of tumor lesions. As part of the clinical routine analysis, PET/CT is mostly analyzed in a qualitative way by experienced medical imaging experts. Additional quantitative evaluation of PET information would potentially allow for more precise and individualized diagnostic decisions.A crucial initial processing step for quantitative PET/CT analysis is segmentation of tumor lesions enabling accurate feature extraction, tumor characterization, oncologic staging and image-based therapy response assessment. Manual lesion segmentation is however associated with enormous effort and cost and is thus infeasible in clinical routine. Automation of this task is thus necessary for widespread clinical implementation of comprehensive PET image analysis.Recent progress in automated PET/CT lesion segmentation using deep learning methods has demonstrated the principle feasibility of this task. However, despite these recent advances tumor lesion detection and segmentation in whole-body PET/CT is still a challenging task. The specific difficulty of lesion segmentation in FDG-PET lies in the fact that not only tumor lesions but also healthy organs (e.g. the brain) can have significant FDG uptake; avoiding false positive segmentations can thus be difficult. One bottleneck for progress in automated PET lesion segmentation is the limited availability of training data that would allow for algorithm development and optimization.
To promote research on machine learning-based automated tumor lesion segmentation on whole-body FDG-PET/CT data we host the autoPET-II challenge - as a successor of the autoPET challenge - and provide a large, publicly available training data set on TCIA:
AutoPET-II is hosted at the MICCAI 2023: ![]()
Grand Challenge
More information about the challenge can be found on Grand Challenge.Task
I.) Accurate detection and segmentation of FDG-avid tumor lesions in whole body FDG-PET/CT. The specific challenge in automated segmentation of FDG-avid lesions in PET is to avoid false-positive segmentation of anatomical structures that have physiologically high FDG-uptake (e.g. brain, kidney, heart, etc…) while capturing all tumor lesions.II.) Robust behavior of the algorihtms in term of moderate changes in acquisition protocol or acquisition site. This will be reflected by the test data which will be drawn partly from the same distribution as the training data and partly from a different hospital with a similar, but slightly different acquisition setup.
Database
The challenge cohort consists of patients with histologically proven malignant melanoma, lymphoma or lung cancer as well as negative control patients who were examined by FDG-PET/CT in two large medical centers (University Hospital Tübingen, Germany & University Hospital of the LMU in Munich, Germany).
All PET/CT data within this challenge have been acquired on state-of-the-art PET/CT scanners (Siemens Biograph mCT, mCT Flow and Biograph 64, GE Discovery 690) using standardized protocols following international guidelines. CT as well as PET data are provided as 3D volumes consisting of stacks of axial slices. Data provided as part of this challenge consists of whole-body examinations. Usually, the scan range of these examinations extends from the skull base to the mid-thigh level. If clinically relevant, scans can be extended to cover the entire body including the entire head and legs/feet.
🎥 PET/CT acquisition protocol
University Hospital Tübingen: Patients fasted at least 6 h prior to the injection of approximately 350 MBq 18F-FDG. Whole-body PET/CT images were acquired using a Biograph mCT PET/CT scanner (Siemens, Healthcare GmbH, Erlangen, Germany) and were initiated approximately 60 min after intravenous tracer administration. Diagnostic CT scans of the neck, thorax, abdomen and pelvis (200 reference mAs; 120 kV) were acquired 90 sec after intravenous injection of a contrast agent (90–120 ml Ultravist 370, Bayer AG). PET Images were reconstructed iteratively (three iterations, 21 subsets) with Gaussian post-reconstruction smoothing (2 mm full width at half-maximum). Slice thickness on contrast-enhanced CT was 2 or 3 mm.
University Hospital of the LMU in Munich: Patients fasted at least 6 h prior to the injection of approximately 250 MBq 18F-FDG. Whole-body PET/CT images were acquired on state-of-the-art PET/CT scanners (Siemens Biograph mCT, mCT Flow and Biograph 64, GE Discovery 690) and were initiated approximately 60 min after intravenous tracer administration. Diagnostic CT scans of the neck, thorax, abdomen and pelvis (100–190 mAs; 120 kV) were acquired 90 sec after weight-adapted intravenous injection of a contrast agent (Ultravist 300, Bayer AG or Imeron 350, Bracco Imaging Deutschland GmbH). PET Images were reconstructed iteratively (three iterations, 21 subsets) with Gaussian post-reconstruction smoothing (2 mm full width at half-maximum). Slice thickness on contrast-enhanced CT was 3 mm.
⌛ Training and test cohort
Training cases: 1,014 studies (900 patients)
Test cases (final evaluation): 200 studies
Test cases (preliminary evaluation): 5 studies
A case (training or test case) consists of one 3D whole body FDG-PET volume, one corresponding 3D whole body CT volume and one 3D binary mask of manually segmented tumor lesions on FDG-PET of the size of the PET volume. CT and PET were acquired simultaneously on a single PET/CT scanner in one session; thus PET and CT are anatomically aligned up to minor shifts due to physiological motion.
Training set
Training data consists of 1,014 studies acquired at the University Hospital Tübingen and is made publicly available on TCIA (as DICOM, NiFTI and HDF5 files). After download, you can convert the DICOM files to e.g. the NIfTI format using scripts provided here.
DICOM:NiFTI:
If you use this data, please cite:
Gatidis S, Kuestner T. A whole-body FDG-PET/CT dataset with manually annotated tumor lesions (FDG-PET-CT-Lesions) [Dataset]. The Cancer Imaging Archive, 2022. DOI: 10.7937/gkr0-xv29
Preliminary test set
For the self-evaluation of participating pipelines, we provide access to a preliminary test set. The preliminary test set uses the same imaging data as the final test set, but consists of 5 studies only.
The access to this preliminary set is restricted and only possible through the docker containers submitted to the challenge, and only available for a limited time during the competition. The purpose of this is that participants can check the sanity of their approaches.
Final test set
The final test set consists of 200 studies. Test data will be drawn in part (1/4) from the same source and distribution as the training data. The majority of test data (3/4) however will consist of oncologic PET/CT examinations that were drawn from different sources reflecting different domains and clinical settings. We will not disclose details of test data as we aim to avoid fine-tuning of algorithms to the test data domain.
🗃️ Data pre-processing and structure
In a pre-processing step, the TCIA DICOM files are resampled (CT to PET imaging resolution, i.e. same matrix size) and normalized (PET converted to standardized update values; SUV). For the challenge, the pre-processed data will be provided in NifTI format. PET data is standardized by converting image units from activity counts to standardized uptake values (SUV). We recommend to use the resampled CT (CTres.nii.gz) and the PET in SUV (SUV.nii.gz). The mask (SEG.nii.gz) is binary with 1 indicating the lesion. The training and test database have the following structure:
|--- Patient 1
|--- Study 1
|--- SUV.nii.gz (PET image in SUV)
|--- CTres.nii.gz (CT image resampled to PET)
|--- CT.nii.gz (Original CT image)
|--- SEG.nii.gz (Manual annotations of tumor lesions)
|--- PET.nii.gz (Original PET image as actictivity counts)
|--- Study 2 (Potential 2nd visit of same patient)
|--- ...
|--- Patient 2
|--- ...
import nibabel as nib
SUV = nib.load(os.path.join(data_root_path, 'PETCT_0af7ffe12a', '08-12-2005-NA-PET-CT Ganzkoerper primaer mit KM-96698', 'SUV.nii.gz'))
PETCT_0af7ffe12a is the fully anonymized patient and 08-12-2005-NA-PET-CT Ganzkoerper primaer mit KM-96698 is the anonymized study (randomly generated study name, date is not reflecting scan date).
✒ Annotation
Two experts annotated training and test data: At the University Hospital Tübingen, a Radiologist with 10 years of experience in Hybrid Imaging and experience in machine learning research annotated all data. At the University Hospital of the LMU in Munich, a Radiologist with 5 years of of experience in Hybrid Imaging and experience in machine learning research annotated all data.
The following annotation protocol was defined:
Step 1: Identification of FDG-avid tumor lesions by visual assessment of PET and CT information together with the clinical examination reports.
Step 2: Manual free-hand segmentation of identified lesions in axial slices.
Evaluation
Evaluation will be performed on held-out test cases of 200 patients. Test data will be drawn in part (1/4) from the same source and distribution as the training data. The majority of test data (3/4) however will consist of oncologic PET/CT examinations that were drawn from different sources reflecting different domains and clinical settings. A combination of two metrics reflecting the aims and specific challenges for the task of PET lesion segmentation:
- Foreground Dice score of segmented lesions
- Volume of false positive connected components that do not overlap with positives (=false positive volume)
- Volume of positive connected components in the ground truth that do not overlap with the estimated segmentation mask (=false negative volume)
A python script computing these evaluation metrics is provided under https://github.com/lab-midas/autoPET.
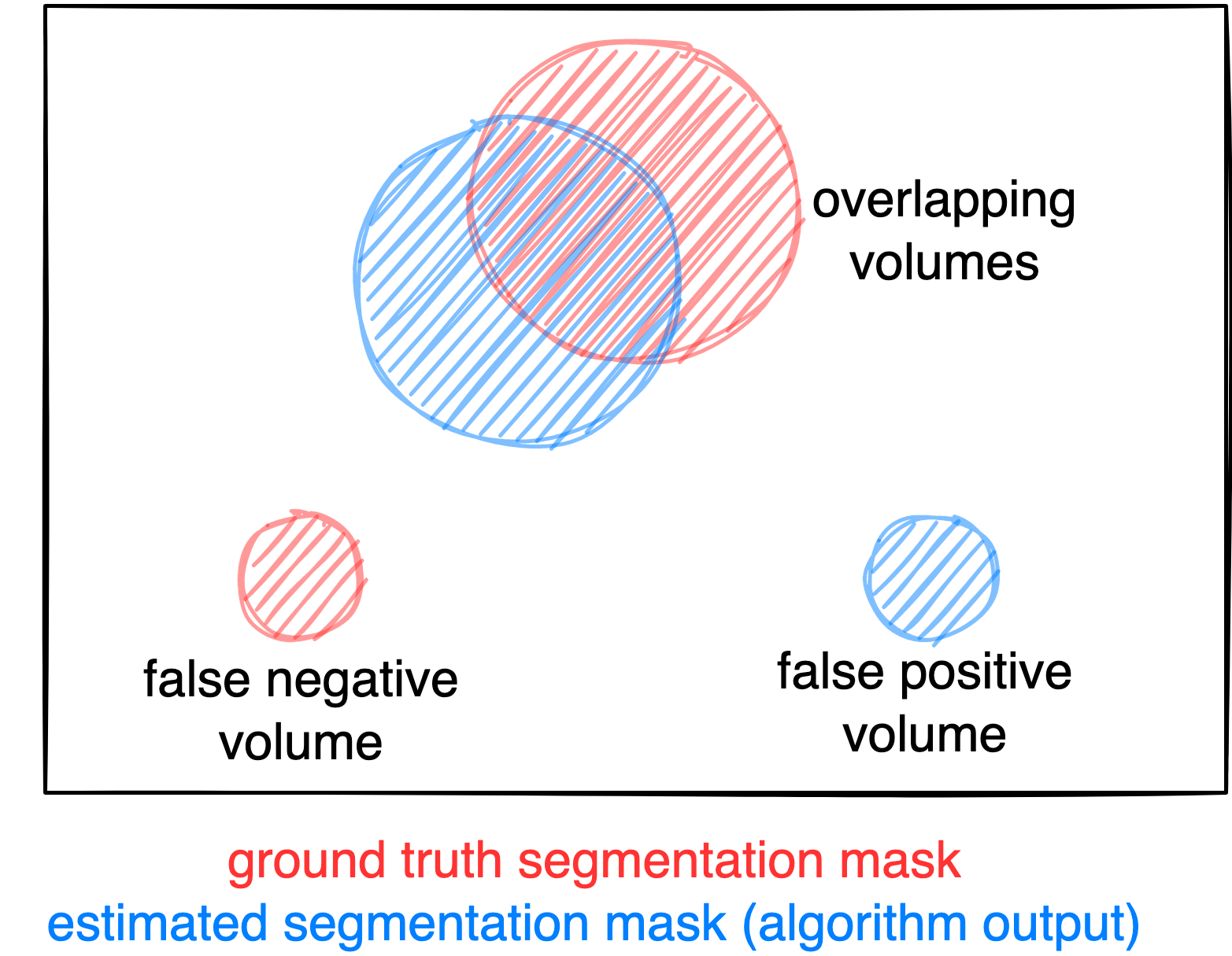
Figure: Example for the evaluation. The Dice score is calculated to measure the correct overlap between predicted lesion segmentation (blue) and ground truth (red). Additionally special emphasis is put on false positives by measuring their volume, i.e. large false positives like brain or bladder will result in a low score and false negatives by measuring their volume (i.e. entirely missed lesions).
Ranking
The submitted algorithms will be ranked according to:
Step 1: Separate rankings will be computed based on each metric (for metric 1: higher Dice score = better, for metrics 2 and 3: lower volumes = better)
Step 2: From the three ranking tables, the mean ranking of each participant will be computed as the numerical mean of the single rankings (metric 1: 50 % weight, metrics 2 and 3: 25 % weight each)
Step 3: In case of equal ranking, the achieved Dice metric will be used as a tie break.
Award category 1
The metrics (Dice, FP, FN) will be directly used to generate the leaderboard. (for Dice: higher score = better, for FP or FN: lower volumes = better)
Award category 2
The goal of award category 2 is to identify contributions, that provide stable results over different data sets. However, low variation of performance across different environments is only meaningful if - in addition - performance itself is acceptable. There is a trade-off between accuracy and variance of results. Therefore - in this category - the ranking will be defined in terms of variance regarding the same metrics as in category 1. However, only contributions that have above median performance (compared to all contributions) regarding the Dice metric will be considered. This is to avoid trivial submissions with constant low performance.
Award category 3
It will be evaluated by a jury of at least 2 independent experts in the field.
Please note that participants can only contribute one algorithm for all three categories. We will not accept different contributions for each category.
Codes and Models
Codes
https://github.com/lab-midas/autopet
Models
Models and documentation of the submitted challenge algorithms can be found in the Leaderboard.
Leaderboard
Category 1
| # | Team | Mean Position | Dice (Position) | False Negative Volume (Position) | False Positive Volume (Position) | Model | Documentation |
|---|---|---|---|---|---|---|---|
| 1 | BAMF Health | 4 | 0.360 (3) | 6.017 (2) | 87.839 (3) | Model | Preprint |
| 2 | Blackbean | 6 | 0.372 (1) | 6.950 (4) | 161.392 (12) | Model | Preprint |
| 3 | anissa218 | 8.5 | 0.364 (2) | 13.200 (12) | 105.858 (6) | Model | Preprint |
| 4 | Zhack | 9.25 | 0.358 (5) | 12.572 (11) | 100.083 (5) | Model | Preprint |
| 5 | cv:hci | 10.25 | 0.338 (8) | 8.503 (5) | 98.294 (4) | Model | Preprint |
| 6 | Isensee | 11 | 0.350 (6) | 16.641 (16) | 65.492 (2) | Model | Preprint |
| 7 | zstih | 12 | 0.340 (7) | 9.607 (7) | 135.416 (9) | Model | Preprint |
| 8 | nnUNet (Baseline) | 12.5 | 0.359 (4) | 13.549 (13) | 176.430 (13) | Model | Preprint |
| 9 | FCDN | 13 | 0.331 (9) | 10.213 (8) | 122.449 (8) | Model | Preprint |
| 10 | agaldran | 13.25 | 0.315 (13) | 5.275 (1) | 156.658 (11) | Model | Preprint |
| 11 | amrn | 16.25 | 0.323 (11) | 6.4733 (3) | 334.719 (18) | Model | Preprint |
| 12 | ahnssu | 17.25 | 0.330 (10) | 10.931 (9) | 217.306 (15) | Model | Preprint |
| 13 | shadab | 19.25 | 0.322 (12) | 12.358 (10) | 253.917 (16) | Model | Preprint |
| 14 | DIKU | 20.75 | 0.266 (17) | 14.064 (14) | 110.077 (7) | Model | Preprint |
| 15 | MAILAB-NM | 21 | 0.292 (15) | 14.994 (15) | 148.012 (10) | Model | Preprint |
| 16 | IMIT-RJH | 21.25 | 0.274 (16) | 8.553 (6) | 203.505 (14) | Model | Preprint |
| 17 | MOOSE | 21.25 | 0.180 (18) | 68.073 (18) | 50.638 (1) | Model | Preprint |
| 18 | Y.Chen-PET-MiLab | 24.5 | 0.300 (14) | 17.976 (17) | 322.316 (17) | Model | Preprint |
Category 2
| # | Team | Mean Position | Dice/std (Position) | False Negative Volume * std (Position) | False Positive Volume * std (Position) | Model | Documentation |
|---|---|---|---|---|---|---|---|
| 1 | BAMF Health | 1.75 | 0.984 (2) | 112.607 (1) | 15695.497 (2) | Model | Preprint |
| 2 | Blackbean | 3.25 | 0.991 (1) | 304.211 (4) | 60298.275 (7) | Model | Preprint |
| 3 | cv:hci | 3.25 | 0.940 (4) | 228.906 (2) | 19315.154 (3) | Model | Preprint |
| 4 | anissa218 | 4.75 | 0.964 (3) | 946.061 (8) | 23938.101 (5) | Model | Preprint |
| 5 | Zhack | 5.25 | 0.937 (5) | 900.842 (7) | 23587.635 (4) | Model | Preprint |
| 6 | Isensee | 6.25 | 0.916 (7) | 1294.504 (10) | 9848.754 (1) | Model | Preprint |
| 7 | nnUNet (Baseline) | 7.25 | 0.935 (6) | 972.116 (9) | 76533.492 (8) | Model | Preprint |
| 8 | zstih | 7.25 | 0.892 (9) | 440.805 (5) | 46443.912 (6) | Model | Preprint |
| 9 | shadab | 7.75 | 0.905 (8) | 888.072 (6) | 138552.610 (9) | Model | Preprint |
| 10 | amrn | 8.25 | 0.867 (10) | 282.706 (3) | 264932.967 (10) | Model | Preprint |
Category 3
Scientific contribution: agaldran
Engineering contribution: Isensee
Organizers


Medical Image and Data Analysis (MIDAS.lab)

